
開発マネージャーのYです。
今回の記事では、今後一緒に働くかもしれない求人情報からここまで到達したエンジニアの方と、今後一緒に働くことになった社内のエンジニア向けに、2年前までオンプレミスでサービスを稼働させていた当時から、AWSに以降した際の色々や、どんな構成でサービスを動かしているか、のイメージを掴んでもらうことを目的として簡単(細かく書くとまとまらないので許してください)にまとめます。
移設前のオンプレ
オンプレ(=オンプレミス)。最近ではクラウドのサービス提供事業者も増え、サービスも充実し、クラウドを使う会社(サービス)が増えてきていますが、データセンターを借りて、自前でハードを調達し、物理サーバをちゃんと管理している会社もまだまだ多いと思います。
そう、弊社も2020年まではオンプレで、池袋のデータセンターでサービスを動かしてていました。

台数は200台弱くらいです。
見ての通り、ベニヤ板の上に裸のマザーボード、こんなサーバで運用していました。懐かしい。このような形で2000年中頃から、当初はマンションで運用していた(その当時は私はいないです)そうです。
ご想像の通り、200台近くある、ということは、、、
寿命が10年とした前提だと年間平均20台くらい寿命がくるわけですね。しかもタイミングは読んでくれません。
人がたくさんいれば問題ないのでしょうが、限られた人員で運用していく中で夜中にデータセンターに行かなきゃいけなかったり、壊れたハードをすぐ代替品手配して、とかもなかなか大変です。
トラブル発生!!
ありがたいことに、しっかりと右肩上がりでPVが伸びていくサービス。それと反対に徐々に増える劣化によるハードトラブル。
ついに、2020年3月の週末、連日夜間のトラフィックでアラートが発生しまくる事態となりました。
オンプレでの拡張か、AWSか。
以前からずっと検討をしてきていましたが、これを機にAWSに一気に舵を切ることに。とはいえ即切り替えなどできるわけもなく、これから一進一退の移行作業が始まりました。
当初、社内リソースが限られていた(余裕で片手で数え切れるエンジニアしかいない)関係で、AWSのコンサルティングサービスなどを行っている外部の会社に委託することも考えていました。が、移設作業のみで約2000万以上(かつ動作保証とかなし)で、社内でやるしかないなーとという話にはなっていたのですが。。。
この200台近くのオンプレ⇨AWSへの切り替えは、途中途中で多少のトラブル発生、切り戻しなどは行ったものの、結果的に最長でのサービスダウンダイム1時間も発生させずに、移行を完了させました。
1st step(トラブル発生の翌日)
初めは、AWSに一部のLBとウェブサーバだけを移設することを試みます。
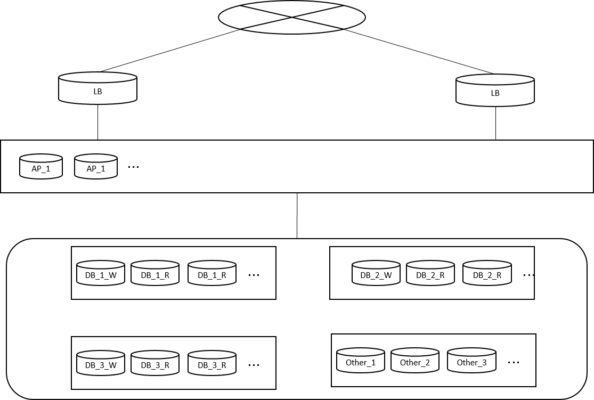
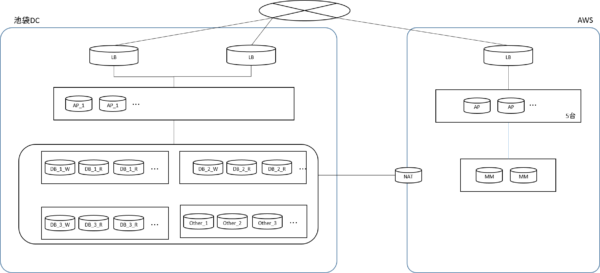
一番初めは、LBとAPサーバのを移設し、DBは基本的にオンプレを参照する構成で一部のトラフィックをAWSに向けることを試しました。連日のトラブル発生の翌日にこの構成に変更し、1/7のトラフィックをAWSに向ける状態まで進めました。
(LB:load balancer, AP:application server, DB (3系統)、Othe:cassandraやその他リソース、MM:memcache)
2nd step(トラブル発生の翌々日)
上記構成では、DBとの接続が一般のインターネット回線経由での通信だったため、負荷が増えると通信にトラブルが色々発生しました。1/5にの割り振りにもトライしましたが、通信の遅延が発生する状態となり、参照系DBの一部をAWSにも設置します。
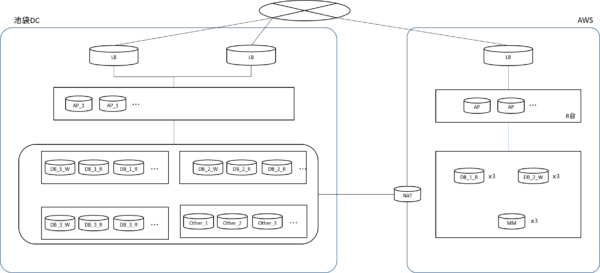
これにより、1/5(=20%)までAWSへのトラフィック割り振りができました。
1週間後
こんな調子で、徐々に移設を進め、翌週にはトラフィックの50%はAWSに向けた状態へと切り替え、過去最高PVを達成します。
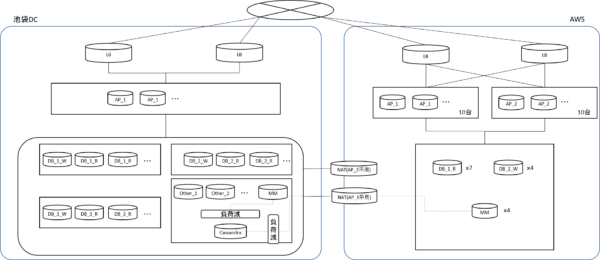
そして移設完了へ
週末のトラブル発生から約1週間でAWSへの移行の目処がたち、その後データセンターの解約の期日に合わせて最終の切り替え準備を進めました。
一番最後は各DBのマスタのみがオンプレに存在し、それ以外は全てAWSに移設した状態で、マスタの切り替え作業のみを実施し、AWSへの完全移行を完了しました。
この移設で結構珍しかったかもしれないこと
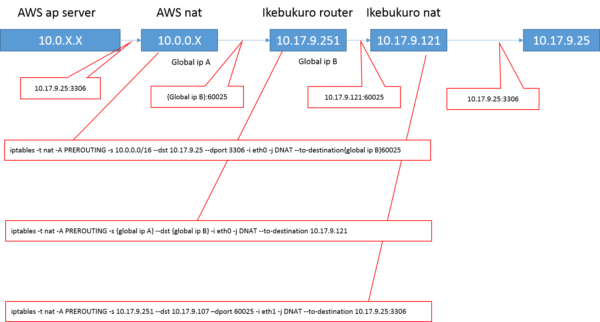
この移設作業で、データセンターxAWS間で通信をiptablesのNAT変換のみを使って行ったことは結構珍しい手法だったかもしれません。
当初よりAWS側からは、一方的にデータセンターを参照とし、データセンター側からはAWSを参照しない前提としました。
AWSからのリクエストは全て旧環境でのIP、portをそのまま利用してアクセスできるようにしました。AWS側では、データセンター側へのリクエストが全てportに割り振られて制御されるようにnat変換の設定を行い、さらに、データセンター側では、port番号からリクエスト対象のサーバの特定portに通信するための変換を改めて行うことで、APサーバやDBサーバの連携を、旧オンプレ環境の時とほぼ変わりなく運用できる状態としました。
弊社では、ただアプリケーションを作るだけではありません
ということで、今回はインフラ周りのお話をさせていただきました。
アプリケーションの開発だけを行っているとこういったことには触れられなかったり、インフラの専門部隊だけがこういった仕事をする会社も多いと思います。
また、ある程度の台数が必要な規模のインフラに触ったことがない、というエンジニアの方も多いと思います。
弊社では、特に業務が縦割りでもないですし、積極的に色々学びたい、やってみたい方にはどんどん機会を提供します。
「アプリケーション開発だけでなく、インフラもやって見たい」とか、「インフラも触りつつ幅広く技術を学びたい」という方にはとても良い環境と思います。
興味がある方には、今回の話を更に細かく記載した資料なども提供可能です。
新たな仲間も引き続き募集中です。フルスタックエンジニアを目指すあなたをお待ちしています。
文:開発部Y

